

Mar 3, 2017
10 Tips to improve your TM1 application
Over the years your TM1 application will grow, you might create new cubes, create/update rules or TM1 processes, create new elements…. All these changes will have an impact on your application performance.
If you want to minimize this impact, here are 10 tips that you should look at. When you design an application, it is always difficult to find the right balance between users requirements, design standards and performance that is why these tips might not all be relevant to your application.

1. Improve TM1 rules
As the size and the complexity of systems grow, your TM1 rule files become more complex so if you do not want to lose calculation time, here are some best practices that you can follow:
- Use skipcheck algorithm.
- Use TM1 attributes instead of text functions: Text comparison in TM1 is generally slower than operating on attributes.
- Try to create consolidations instead of rules: Consolidation is the fastest way to calculate values:
Use FTE as a consolidation of Hours with a weight of (1/8)
instead of
[‘FTE’]=[‘Hours’]/8;
Area statements are faster than IF statements:
['A'] = N: 1;['B'] = N: 0;
instead of
[{‘A’,’B’}] = N: IF( !Column @= ‘A’ , 1 , 0 ) ;
Pulse for TM1 can help you to follow these best practices. The validation report can help you to validate your best practice rules against your model.
2. MTQ (Multi-Threaded Query)
Even if TM1 was already fast, IBM made TM1 even faster with the introduction of MTQ with v10.2. Instead of doing the calculation on one CPU, TM1 can now use several CPU at the same time. As IBM recommendations, the best practice is to set the MTQ value such that the maximum available processor cores are used.
3. Run TM1 processes in parallel
Parallel processing is a TM1 feature which unfortunately is not enough used. Imagine for instance that instead of running one TM1 process which copy data for one year, you could run one TM1 process which then launches one TM1 process per months (12 processes running at the same time) using TM1RUNTI.
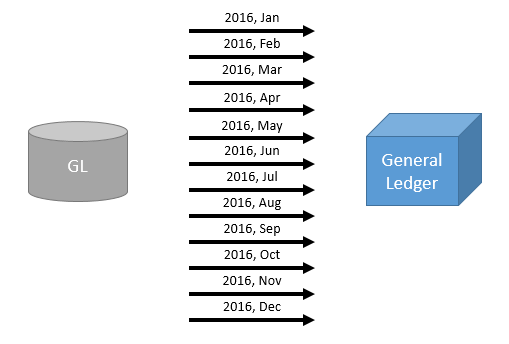
Instead of
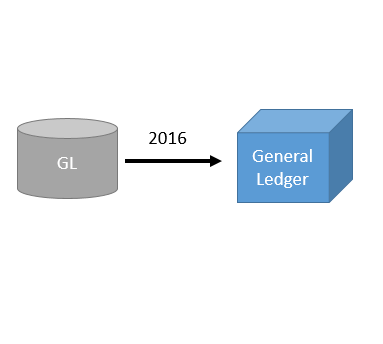
If you want to do parallel processing, I highly recommend you to use Hustle. It is a free tool which will help you to handle the number of threads you want to run at the same time.
4. Avoid User Locking
Having users locked and not able to access their data is one of the worst situation for a TM1 Administrator, hopefully it does not happen often in the TM1 world. Here some tips to avoid user locking:
- Turn off cube logging by using CellPutS( ‘NO’, ‘}CubeProperties’, ‘cubename’, ‘LOGGING’ ) instead of CubeSetLogChanges( ‘cubename’, 0 ).
- Avoid dimensions update during working hours ( Split metadata update and data update in 2 different TI)
- Use CellGetN with cautious, it can create locking.
- Security Refresh (use processes over rules to update TM1 security).
- Set up Alerts to be the first to know when there is an issue.
5. Train your users
After implementation it is usual for users to develop their own TM1 spreadsheets that may or may not be designed according to best practices. Depending on what they build (Large cube view or do spreading on a high consolidation), it might slow down or even lock TM1 during working hours. In order to avoid these issues you should make sure that they know the TM1 basics:
- Use VIEW function in a slice.
- Use DBRW instead of DBR.
Pulse analyses all Excel workbooks linked to your TM1 application and can help you to identify users who need training.
6. Restart your TM1 server on a weekly basis
TM1 elements that are deleted aren’t removed from the TM1 indexes until a server restart. So if you are frequently removing and adding elements your memory will grow overtime. Restarting the TM1 instance will help removing temporary files.
7. Clean dimensions
The number of elements in dimensions increase over time. Even if it is not an issue for a cube to have lots of “0” cells, having lots of elements in your dimension will slow down all your MDX query or dynamic subsets.
This is relevant only for Large dimensions (>100,000 elements) such as Product or Customer dimensions. Be very careful during this step because if you delete an element, you will lose the data attached to it.
8. Snapshot old data
Rules should be applied only on a specific cube area where data changes. You do not need rules if your data is static such as last year data for example. What you could do is export cube data for the specific year, remove the rules and then load the data back, the data for this year will then be static and it will be much faster to query them.
9. Tune VMM/VMT
TM1 keeps the calculation in memory, the first time you open a cubeview, if it takes more time than the VMT value (default is 5 sec), TM1 will keep this view in memory (TM1 creates a stargate view), next time you open the cubeview, it will be much faster because TM1 will open the stargate view instead of recreating the view from scratch.
VMM is the amount of RAM reserved on the server for the storage of stargate views. Increasing this value will allow TM1 to store more stargate views, which means that TM1 will be much faster but it will consume more memory.
10. Disable anti-virus on the TM1 data folder
Virus scan software can negatively impact your TM1 application performance. You should set up your anti-virus to skip TM1 folders.